Michael Ganslmeier and Tim Vlandas have developed a new approach to measure the fragility of findings in political science. Showing that empirical results can change substantially when researchers vary reasonable and equally defensible modelling choices, they advocate for greater use of systematic robustness checks
Recent controversies around research transparency have reignited longstanding concerns about the fragility of empirical evidence in the social sciences. Headlines tend to focus on cases of misconduct and fraud. However, this often overlooks the degree of sensitivity of results to equally defensible modelling choices in empirical political science research.
Our new study set out to measure the fragility of findings in political science. How much do empirical results change when researchers vary reasonable and equally defensible modelling choices?
To answer this question, we estimated over 3.6 billion regression coefficients across four widely studied topics in political science: welfare generosity, democratisation, public goods provision, and institutional trust – although we report only results for the latter three in this blog post. Each topic is characterised by well-established theories, strong priors, and extensive empirical literatures.
How much do empirical results change when researchers vary reasonable and equally defensible modelling choices?
Our results reveal a striking pattern: the same independent variable often yields not just significant and insignificant coefficients but also a very large number of statistically significant positive and statistically significant negative effects, depending on how the model is set up. Thus, even good-faith research, conducted using standard methods and transparent data, can sometimes produce contradictory conclusions.
Recent advances – such as pre-registration, replication files, and registered reports – have significantly improved research transparency. However, they typically begin from a pre-specified model. And even when researchers follow best practices, they still face a series of equally plausible decisions. They must choose which years or countries to include, how to define concepts like 'welfare generosity', whether and which fixed effects to use, whether and how to adjust standard errors, and so on.
Each of these choices may seem minor on its own, and many researchers already use a wide range of robustness checks to explore their impact. But collectively, these decisions define an entire modelling universe. Navigating that space can have a profound effect on results. Standard robustness checks often examine one decision at a time. Yet this may fail to account for the joint influence of many reasonable modelling paths taken together.
Our goal was not to test a single hypothesis, but to observe how much the sign and significance of key coefficients change across plausible model specifications
To map that model space systematically, we combined insights from extreme bounds analysis and the multiverse approach. We then varied five core dimensions of empirical modelling: covariates, sample, outcome definitions, fixed effects, and standard error estimation. The goal was not to test a single hypothesis, nor indeed to replicate prior studies. Rather, it was to observe how much the sign and significance of key coefficients change across plausible model specifications.
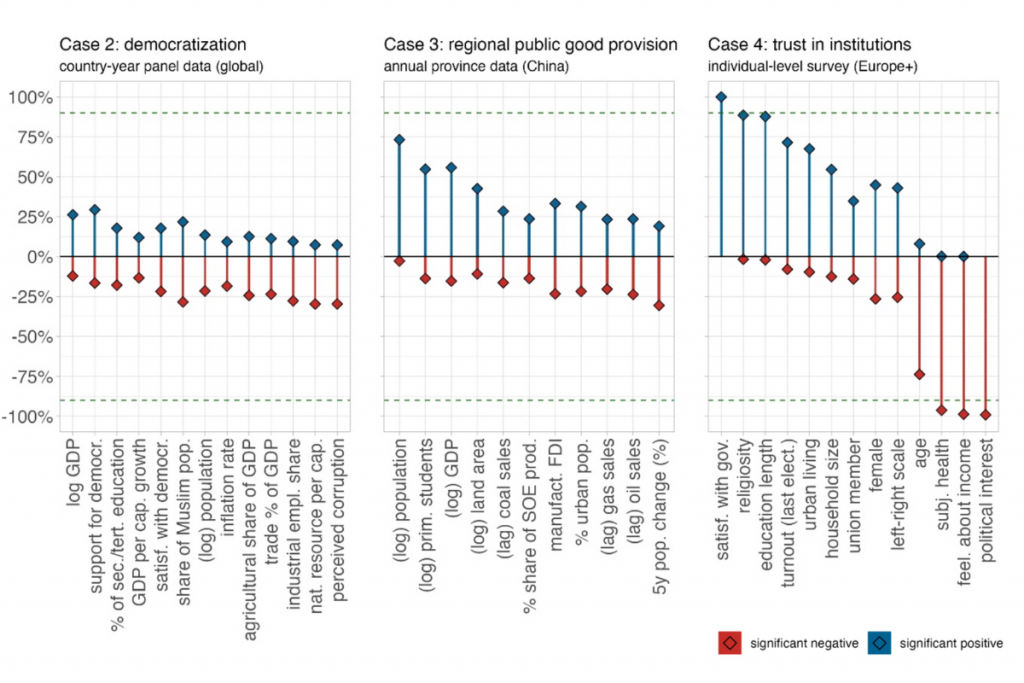
For many variables commonly used to support empirical claims, we found many model specifications where the estimated effect was positive and statistically significant. But we also discovered others where it was strongly negative and statistically significant (see graph below).
One clear implication is that conventional robustness checks, while valuable, may still be too limited in scope. Researchers frequently vary control variables, estimation techniques, or subsamples to assess the stability of their findings. But by examining modelling decisions in isolation, researchers can typically apply these checks sequentially and independently. Our results suggest, however, that this approach can miss the larger picture. It is not just which decisions researchers make, but how their combination determines the stability of empirical results.
Results from our study suggest that is not just which decisions researchers make, but how their combination determines the stability of empirical results
By systematically exploring a wide modelling space, while automating thousands of reasonable combinations of covariates, samples, estimators and operationalisations, our approach can assess the joint influence of modelling choices. This allows us to identify patterns of fragility that are invisible to conventional checks.
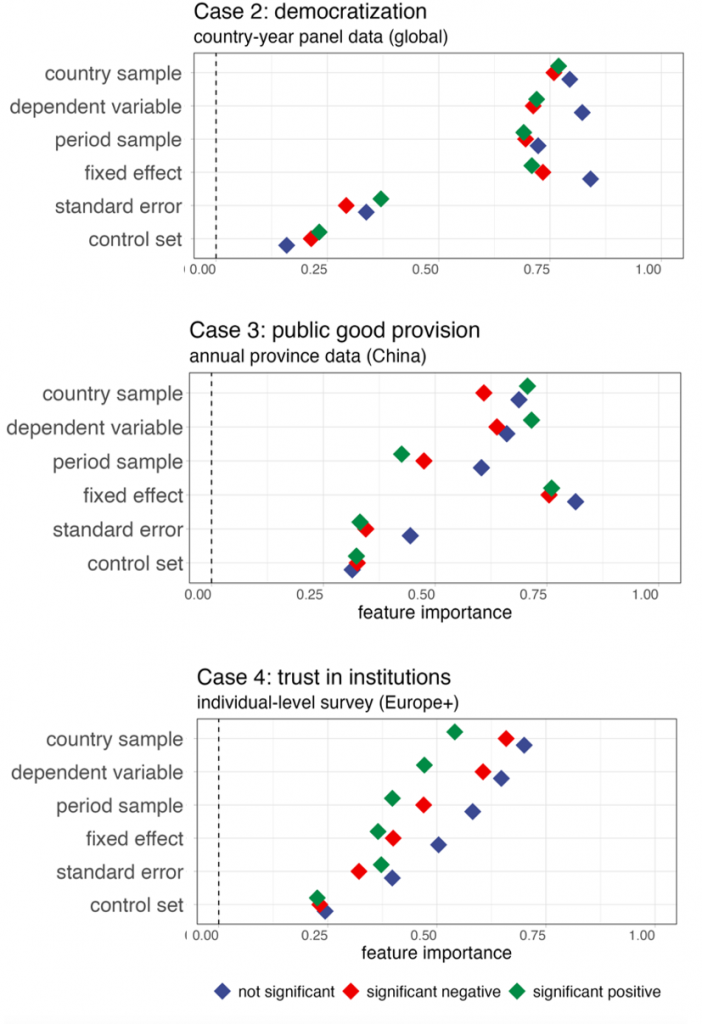
We estimated the feature importance scores for these different model specification choices. To do so, we first extracted a random set of 250,000 regression coefficients from the unrestricted model universe for each topic. Then, we fitted a neural network to predict whether an estimate is 'negative significant', 'positive significant' or 'not significant'.
The graph below shows that it is not the control variables per se that drive the greatest source of variation, but decisions on sample construction. What matters are which countries or time periods researchers include – and how they define key outcomes. These upstream decisions, often made early and treated as background, exert the strongest influence on whether results are statistically significant – and in which direction.
To be clear, the implication of our findings is not that nothing is robust, nor that quantitative social science is futile. On the contrary, our work underscores the value of systematically understanding where results are strong and where (and why) they might be less stable.
With this new approach, we hope to provide an additional tool that researchers can use to carry out systematic robustness checks and to increase transparency. To that end, we provide our code with which future research can analyse and visualise the model space around a result.
This article was originally published on the LSE EUROPP blog on 14 August 2025.



